
Baixando as libs no GIT
Uma das dificuldades em manusear as ferramentas de Big Data é a dificuldade de preparação do ambiente. Atualmente possuímos duas opções para o trabalho, uma seria utilizar as virtuais machines(VMs) no qual temos que dividir recurso da nossa máquina e a outra opção é utilizar recursos na nuvem, que após a utilização devemos excluir o cluster para que não fique cobrando os recursos locados.
No post abaixo vamos preparar o ambiente para executar tarefas no Spark através da execução do próprio eclipse com a linguagem Scala, sem a necessidade de instanciar uma nova VM para processamento da engine.
- Baixar o Scala IDE no site: http://scala-ide.org/
- Após o diretório ser descompactado, abra o Scala IDE atráves de seu executável, clique em file>import. Na janela selecione Projects form git.
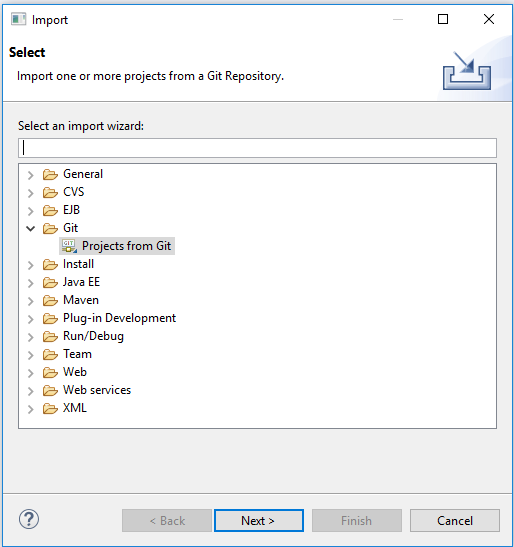
- Selecione a opção Clone URI, colocando a URI: https://github.com/slothbigdata/SlothBigDataSparkLicao.git

- A próxima etapa é selecionar o diretório do seu projeto git e colocar a opção: Import existing Eclipse projects

- Clicando mais uma vez no Next e logo após o Finish, você estará com os pacotes dentro do Spark dentro do Scala IDE.

- Atenção: Os pacotes das bibliotecas do projeto, são de referência a versão 2.11, para alterar a versão clique com o botão direito em: Scala Library container[versão] -> Properties -> Classpath Container e selecione a versão 2.11 do Scala.
Instalação do WinUtils
Para simular um repositório de HDFS dentro do seu PC é necessário a instalação do WinUtils.
- Copie o winutils do projeto do Scala IDE em um diretório local.

- Descompacte o programa para um diretório de execução.
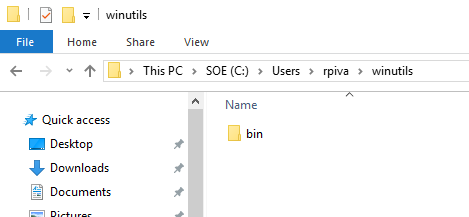
- E defina a variável de ambiente HADOOP_HOME com o diretório descompactado do WinUtils.

- Insira o HADOOP_HOME no PATH informando o diretório bin.

- Reinicie o Scala IDE.
Executando um teste
Para teste vamos executar uma tarefa de contagem de palavras com uma aplicação em Scala.
Para teste vamos executar uma tarefa de contagem de palavras com uma aplicação em Scala.
- Copie para uma pasta o arquivo dados1_word_count.txt que encontra-se no projeto do Scala IDE.
- No caso abaixo eu coloquei o arquivo no diretório: C:\dados\consulta\ e na saida solicitei para criar o diretório wordcountresult com os dados (não crie o diretório do resultado, pois a aplicação dará erro do diretório já existente)
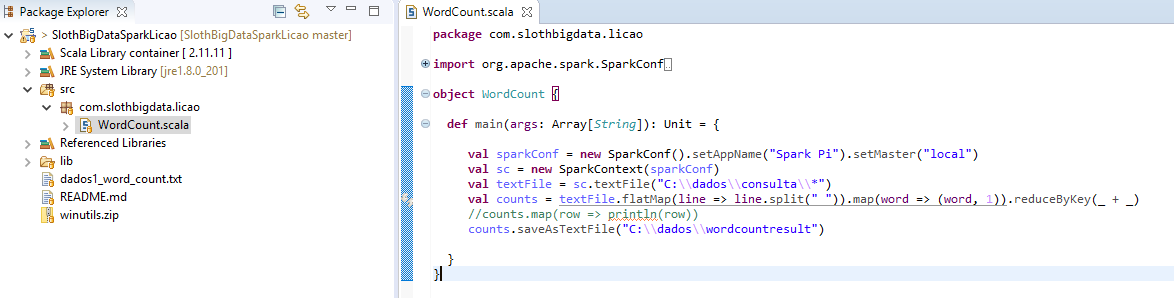
- Clique com o botão direito em cima do código, selecione o menu Run as > 2 Scala Application.

- Visualize o diretório do resultado.

Em caso de dúvidas ou sugestões, escreva nos comentários ou nos mande um email: slothbigdata@gmail.com.
Nenhum comentário:
Postar um comentário